
Page 29 - 金融科技视界2023-2期
P. 29
Technical Tracking
技术追踪
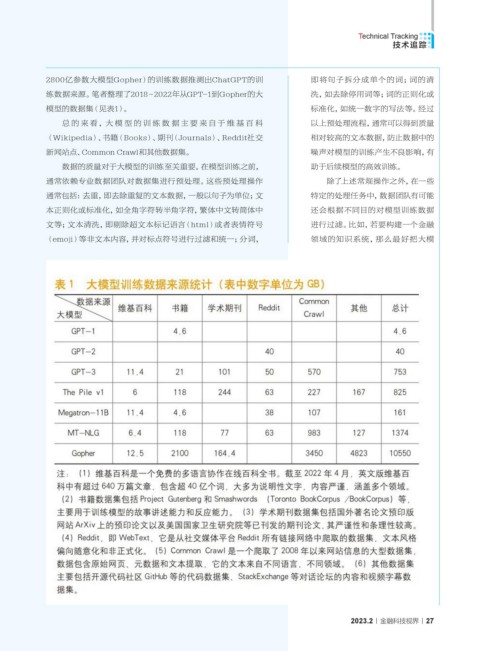
2800亿参数大模型Gopher)的训练数据推测出ChatGPT的训 即将句子拆分成单个的词;词的清
练数据来源。笔者整理了2018~2022年从GPT-1到Gopher的大 洗,如去除停用词等;词的正则化或
模型的数据集(见表1)。 标准化,如统一数字的写法等。经过
总 的来 看,大 模 型 的训 练 数 据 主 要 来 自 于 维 基 百 科 以上预处理流程,通常可以得到质量
(Wikipedia)、书籍(Books)、期刊(Journals)、Reddit社交 相对较高的文本数据,防止数据中的
新闻站点、Common Crawl和其他数据集。 噪声对模型的训练产生不良影响,有
数据的质量对于大模型的训练至关重要。在模型训练之前, 助于后续模型的高效训练。
通常依赖专业数据团队对数据集进行预处理。这些预处理操作 除了上述常规操作之外,在一些
通常包括:去重,即去除重复的文本数据,一般以句子为单位;文 特定的处理任务中,数据团队有可能
本正则化或标准化,如全角字符转半角字符,繁体中文转简体中 还会根据不同目的对模型训练数据
文等;文本清洗,即剔除超文本标记语言(html)或者表情符号 进行过滤。比如,若要构建一个金融
(emoji)等非文本内容,并对标点符号进行过滤和统一;分词, 领域的知识系统,那么最好把大模
2023.2 金融科技视界 27